That's 34 trillion, 400 billion transistors to simulate a human brain.
As of 2024, the GB200 Grace Blackwell GPU has 208 billion MOSFETs[3]. In 2023, AMD's MI300A CPU had 146 billion transistors[3]. In 2021, the Versal VP1802 FPGA had 92 billion transistors[3]. Intel projects 1 trillion by 2030; TSMC suggests 200 billion by 2030.
We'll likely have real-time brain analogs by 2064.
(Aside, these are the dates I've used in my hard sci-fi novel. See my profile for details.)
> * That's 34 trillion, 400 billion transistors to simulate a human brain.*
You forgot about:
1-Astrocytes - more common than neurons, computational, have their own style of internal and external signaling, have bi-directional communication with neurons at the synapse (and are thought to control the neurons)
2-Synapse: a single synapse can be both excitatory and inhibitory depending on it's structure and the permeant ions inside and outside the cell at that point in time and space - are your 400 transistors handling all of that dynamic capability?
3-Brain waves: are now shown to be causal (influencing neuron behavior) not just a by-product of activity. Many different types of waves (different frequencies) that operate very locally (high freq), or broadly (low freq). Information is encoded in frequency, phase, space and time.
This is the summary, the details are even more interesting and complex. Some of the details are probably not adding computational capabilities, but many clearly are.
The main issue is that we're lacking one of the four fundamental circuit components: the memristor [0].
If we had a simple, throw it in a box for five years, stable memristor, we'd have everything we'd need for brain modeling. Being as a memristor is effectively a synapse.
With that, we would want to do everything in the analog domain anyways.
[0] the other three are the resistor, the capacitor, and the inductor.
A quick Google search will find thousands of articles.
It was possible to buy memristor storage devices, but they weren't sufficiently competitive with ordinary flash memory and I believe they're relegated to niche applications such as high erase counts.
I've been googling for a while on these, it's the first I've heard of it. Do you have a link at all? Not trying to troll here, I really am genuinely interested.
- You have significantly undercounted transistors. As of 2024 you can put up to 8.4 terabytes of LPDDR5X memory into an NVidia Grace Blackwell rack. So that's 72 trillion transistors (and another 72 trillion capacitors) right there.
- A GPU executes significantly faster than a neuron.
- The hardware of one GPU can be used to simulate billions of neurons in realtime.
- Why limit yourself to one GB200 NVL72 rack, when you could have a warehouse full? (what happens when you create a mind that's a thousand times more powerful than a human mind?)
You really need to separate the comparison into state (how much memory), and computation rate. I think you'll find that an NVidia GB2000 NVL72 will outperform a brain by at least an order of magnitude. And the cost of feeding brains far exceeds the cost of feeding GB2000's. Plus, brains are notoriously unreliable.
The current generation of public-facing AIs are using ~24Gb of memory, mostly because using more would cost more than can conveniently given away or rented out for pennies. If I were an evil genius looking to take over the world today, I'd be building terabyte-scale AIs right now, and I'd not be telling ANYONE. And definitely not running it in Europe or the US where it might be facing imminent legislative attempts to limit what it can do. Antarctica, perhaps.
> The hardware of one GPU can be used to simulate billions of neurons in realtime.
You mean simulate billions artificial neurons, right?
You can't simulate a single biological neuron yet because it's way too complex and they still don't even understand all of the details.
If they did have all of the details, at minimum you would need to simulate the concentrations of ions internally and externally as well as the electrical field around the neuron to truly simulate the dynamic nature of a neuron in space and time. It's response to stimulus is dependent on all of that and more.
Depends a bit on how certain you are on your preferred answer to the question: is the brain analog or digital? If you think it is predominantly digital, quite a lot of the details of the biochemical mechanisms don't matter. If you think it is predominantly analog, they matter hugely.
Do any serious theories on the brain being predominantly digital hold any water with neuroscientists? I feel like it's fairly well accepted that the brain isn't digital even just with what we do understand about neurons?
Action potentials are digital. Once the neuron hits the trigger threshold, the spike happens at the same amplitude every time.
The process by how the neuron determines whether it's time to fire or not is almost grotesquely analog, in that it is effected by a million different things in addition to incoming spikes.
How much of each process matters for what is the mind-generating part of the brain's work? We don't know.
Myelination (which allows very fast, and digital, communication between neurons) is universal in vertebrates, which points to it being important for intelligence.
As a counterexample, we have cephalopods, which accomplish their impressive cognitive tasks using only 'slow' neurons; they get around the speed limit by having huge axons, which reduce internal resistance. So we know that digital transmission isn't necessary for intelligence, either.
The nature of cognition is a fascinating subject, isn't it!
I don't think it's possible to tell at this point.
If you looked at the operation of a digital computer, you'd find an analog substrate, with some quite interesting properties. Deciding whether the analog substrate is an important semantic element of how the computer worked, or whether its operation should be understand digitally, is as much a (research-driving) leap of faith as anything else.
That's actually a pretty convincing point. If all we were able to understand was the flow of electrons in a transistor and not how they were connected, we wouldn't necessarily be able to conclusively claim that digital computers were indeed digital.
Skull Volcano lair on an island. Geothermal energy to power the place. Seawater for liquid cooling.
Then of course, you also need the beautiful but corruptible woman as some high-up part of the organization. And a chief of security in your evil enterprise with some sort of weird deformity or scarring - preferably on the face.
Protip: If you catch a foreign spy on the island, kill them immediately. Do not explain your master plan to them just before you kill them.
1) There is not enough data in the entire world to train a trillion parameters large language model. And there is limited use for synthetic data, yet (we need an internal adversarial/evolutionary model like AlphaZero for that, which I think will be developed soon, but we are not there yet).
2) Models are not linearly scalable in terms of their performance. There are 8B parameter models (Zephyr-Mistral) routinely outperforming 180B parameter models (Falcon). Skill issue, like they say.
3) Even if you are an evil genius, you need money and computing power. Contrarily to what you might be reading in the media, there isn't much capital available to evil geniuses on a short notice (longer term arrangements might still be possible). And even if you have money, you can't just buy a truckload of H100s. Their sales are already highly regulated.
Solar panels in a place where the sun doesn't even rise for months at a time? That big beefy transmission grid that the Antarctic continent is so famous for? The jillions of oil wells already drilled into the Antarctic?
Antarctica was chosen because the area on the mainland between 90 degrees west and 150 degrees west is the only major piece of land on Earth not claimed by any country[1], which makes it a good place place to locate businesses that do not wish to be subject to regulations on Artificial Intelligences. Plus it's much more inconvenient to attack than it would be if you located it in a volcanic island.
Each of those cells has ~7,000 synapses each of which is both doing some computation and sending information. Further, this needs to be reconfigurable as synaptic connections aren’t static so you can’t simply make a chip with hardwired connections.
You could ballpark that as that’s 400 * 7000 * 86 billion transistors to simulate a brain that can’t learn anything, though I don’t see the point. Reasonably equivalent real time brain emulation is likely much further I’d say 2070 on a cluster isn’t unrealistic, but we’re not getting there on a single chip using lithography.
What nobody talks about is the bandwidth requirements if this isn’t all in hardware. You basically need random access to 100 trillion values (+100t weights) ~100-1,000+ times a second. Which requires splitting things across multiple chips and some kind of 3D mesh of really high bandwidth connections.
Early in 2038, the AI apocalypse begins and all of humanity is powerless to stop it for six days until Unix time rolls over and the AI serendipitously crashes.
Another interesting angle is power consumption. The brain consumes about 20W so that’s ~200pW/neuron. The GPU is 4 orders of magnitude worse at ~2uW/neuron.
The brain also does much more than a GPU. I’m not sure what percentage of the brain could be considered devoted to equivalent computation but is also interesting to think about. I’ve seen that the brains memory is equivalent to ~2PB.
The power of a 12TB hard drive is ~6W. So current tech has a long way to go if it’s ever going to get close to the brain, 2PB storage is about 1kW alone.
That’s pretty impressive for a bunch of goo that resulted from a random process.
Makes me think we are barking up the wrong tree with silicon based computing.
> We'll likely have real-time brain analogs by 2064.
When there’s occasional talk about triple-letter agencies having far-future tech now, I used to wonder what it might be. I guess this is one of those things.
Transistors are much faster than synapses so a few can simulate a bunch of synapses. As a result you can probably get by with like a million times less than your estimate.
Your suggestion actually makes things much harder.
A single “cycle” (and you need ~100-1,000+ cycles per second) would involve ~7,000 synapses per neuron * 86 billion neurons random memory accesses each second. Each of those accesses need to first read the location of memory and then access that memory.
For perspective a video card which is heavily optimized for this only gets you low billions of random memory access per second. True random access across large amounts of memory is hard. Of course if you’re using a 1 million GPU supercomputer you now need to sync all this memory between each GPU every cycle, or have each GPU handle network traffic for all these memory requests…
PS: The article assumes more efficient AI designs for good reason, actually using a neuronal network the size of the brain in real time is prohibative.
The estimate for how many operations per second the brain does is quite a wild guess. It starts out very reasonable, estimating the amount of information the eyes feed to the brain. But from there on it's really just a wild guess. We don't know how the brain processes visual input, we don't know what the fundamental unit of processing in the brain is, or if there is one.
I'm going to go against the grain here and hypothesize that the computational requirements for emulating human reason are much lower than commonly claimed, and probably within the reach of a high end GPU released in the last/next 10 years.
If you look at state of the art pre-trained transformers, they gobble up unfathomable quantities of dense textual data that far exceed what even the most learned and smart humans could traverse in centuries. Yet, their results are barely intelligent.
The human neural network, on the other hand, stores and is able to recall an estimated average of a few bits per waking second for a decade or two, barely a few GB of useful storage [1]. A great deal of effort and substance of the brain is dedicated to compressing the sensory input into an internal representation useful for rational though - a problem much simplified for a text-fed neural network. The ability of blind and deaf people (or even blind-deaf) for rational reasoning show these ancillary tasks are not intrinsic to human reason.
So things seem to indicate that what we lack is not hardware, but the right architectures and algorithms to unlock human level reason, the exceptionally tight self training loop of humans that can make sense of the world and even push humanity's understanding further using only a few GB of compressed training data.
[1] LANDAUER TK. How much do people remember ‐ some estimates of the quantity of learned information in long‐term‐memory.
> If you look at state of the art pre-trained transformers, they gobble up unfathomable quantities of dense textual data that far exceed what even the most learned and smart humans couldn't traverse in centuries. Yet, their results are barely intelligent
Actually this is untrue. Yann Lecun himself said it. A kid at the age of 6 has had much much more data go through his brain (based on the visual data) than what any transformer has ingested. Moreover, words are already compressed data with a lot of lost information, nowhere near the raw experience about the world that our brains have. On top of that there's the evolutionary stuff.
> Moreover, words are already compressed data with a lot of lost information
That's exactly the point, 99.9% of the information processed by the 6 year old has went into training his visual cortex, a subsystem not necessary for reasoning. This will eventually be used 8 hours a day for transforming visual representation of text on a computer screen into a compressed textual form which the inner rational loop can easily manipulate. The holy grail of AI, for anything but artistic creation, is just this inner loop.
This sounds like a huge oversimplification. A lot of knowledge doesn't come in the form of words, animals, early humans, kids, all don't have speech systems yet are capable of reasoning. You can't become Mozart just by reading the theory of his work, you can't become an expert at anything just by reading the theory in fact, even though it lifts you up. There's definitely things that you know and that aren't in the form of words.
> There's definitely things that you know and that aren't in the form of words.
But are they necessary for reasoning? Records of deaf-blinds with IQs a few standard deviations above average seem to suggest even highly restricted sensory inputs can allow for rational thought. It stretches credulity that you could convey more than a few bits of meaning per second to a child purely by hand gestures and touch, let alone the exabytes claimed.
Of course someone like Yann Lecun will say scale is the only solution, he leads one of the juggernauts that uses scale as a competitive moat. We shouldn't expect AI researchers in positions of power to be any less vane, power hungry or human than any other humans.
This is on point that you mention IQ, since in IQ itself, only a single test includes words. The rest is about pattern recognition, working memory, spatial capabilities and other stuff I don't remember. So in other words, the metric you use as a benchmark for good reasoning barely measures the literacy
Okay, but that's a markedly different problem than the information density of the training data. It's: "can a rational machine trained only with natural language descriptions of the world form complex representations of it and solve associated problems described only in natural language?".
For you and me, a verbal description of a pattern test such as "You are given seven squares. Square A contains a filled cross in the upper left position, an empty circle in the middle... etc." would send us grasping for pen and paper. But with training many people can play mental chess, there are famous blind theoretical physicists and so on. This all seems to suggest that natural language could be called "Turing complete", to bastardize the term, for describing the real world to a rational entity and formulating solutions to real world problems.
It is more than a wild guess, it is a guess based on the outdated perceptron model of the brain.
Active dendrites the that can do operations like xor before anything reaches the soma, or use spike timing, once again before the soma are a couple of examples.
SNNs, or spikey artificial NNs have been hitting limits of the computable numbers.
Riddled basins as an example, which are sets with no open subsets. Basically any circle you can draw will always contain at least one point on a boundary set.
It also blows my mind that that, even though DNA seems to just code for proteins and does not store a schematic for a brain in any way that we've been able to decipher so far, human eggs pretty reliably end up growing into people who 9 months after conception already have a bunch of stuff, including visual processing, working. Of course the DNA is not the only input, there is also the mother's body, the whole process of pregnancy, but I don't know how that contributes to the new baby being able to enter the world already intelligent.
It's possible that I'm not aware of some breakthroughs on this topic, though.
I had a DevOps engineer describe their deployment automation system as a "Giant Rube Goldberg Machine". Which of course, all programming is a giant Rube Goldberg machine, if you think about it. If you take the "Goldberg" analogy to mean "Haphazard" and not well-thought out intentional structuring, I suppose it'd be more appropriate to compare a well-written application to a mechanical swiss watch.
Living beings are more "Rube Goldberg" than "Swiss Watch" - by virtue that they came to being guided not by intention, but circumstance.
I worked on a 25 year project that stretched the tech many times in its life.
On many occasions to get ambitious things to work despite a lack of good support, special subsystems were created with whatever wacky solution could be made to work, wrapped in sane surface API’s so the system as a whole could remain organized and accomplish the task well.
Five or so years after any of these were created, they could have easily been replaced with more reasonable code. But they worked reliably and efficiently. Their API’s were sensible and stable. So they accumulated.
If you reviewed all the code as a whole for the first time it was like finding a secret circus.
DNA does a lot more than coding for proteins. It also controls how genes are expressed (how same gene does different things in different contexts) and how cells differentiate into different types (neurons, skin, muscle, etc) depending on location.
In this way, DNA does control the blueprint for the brain, down to the initial generic wiring scheme of the cortex - six layers of differentiated neuron types, with a specific pattern of inter-connectivity. As a rough analogy, you could think of this DNA-controlled initial wiring scheme as something like an untrained transformer... the architecture is there, but won't do anything useful until it has been exposed to a lot of data, which will complete the wiring scheme (synapses = brain's model weights).
The brain is going to start to learn as soon as it has sufficiently developed, which is certainly before birth, and newborn babies have been shown to already respond to things like their mothers voice which they were exposed to in the womb.
Intelligence - ability to learn - is different from knowledge. A newborn baby has very little knowledge, but it does have intelligence since that comes from the brain architecture, hence ability to learn, that our DNA "encodes".
The story of what we know so far about the development process is fascinating and captured in this book "Endless Forms Most Beautiful" by Sean B. Carroll (2005)
Yes electricity. Just like when you open up a ssd and inspect it under a microscope, its very hard to physically identify software stored on that disc. Same with human cells. Probably some electric layer containing programs of the human body.
It's because nature never actually had to solve that problem: "how do we encode the structure we have here into genes and chromosomes so that it can procreate".
The genes randomly mutate, and their result is subject to fitness testing.
The fascinating thing about evolution is that it's not actually necessary. The "unevolved" creatures persist just fine. The continued survival of cockroaches and whatnot proves that evolving to human levels is superfluous.
I'm thinking out loud here, but what if it's akin to a copy mechanism, or compression expander algorithm like unzipping a file?
The Sperm carries the requisite DNA to activate the egg, which then just executes the body's Replicate() method. The sperm being required is so people don't spontaneously get pregnant.
The DNA coding for proteins is just to build the replicate() method, which then starts copying attributes from the host's (read: mother's) body. Much like how there are differences in compression/expansion algorithms (zip, tar, gz, etc..), the sperm that initiates the replication/unpacking adds non-neutral variance, hence the genetic traits of both parents present in the child.
Put a different way, why reinvent the wheel if I could just grab the memoized visual processing from the parent? Then, if a trait isn't present on the host, say, mid-digital hair, I (as the replication algorithm), "wouldn't know what I wouldn't know" which could perhaps be seeing as synonymous with "evolution."
I remember people discovering that the retina neurons were actually in a very non-common and much less connected geometry than most of our neurons, what meant that the numbers on that page were (an unknown number of) orders of magnitude smaller than reality.
Not really. The brain doesn't do operations per second like a computer. What he is guessing is that if so many operations per second can produce similar results to a certain volume of brain, in this case the retina, then maybe that holds for the rest of the brain. It seems to me a reasonable guess that appears to be proving approximately true.
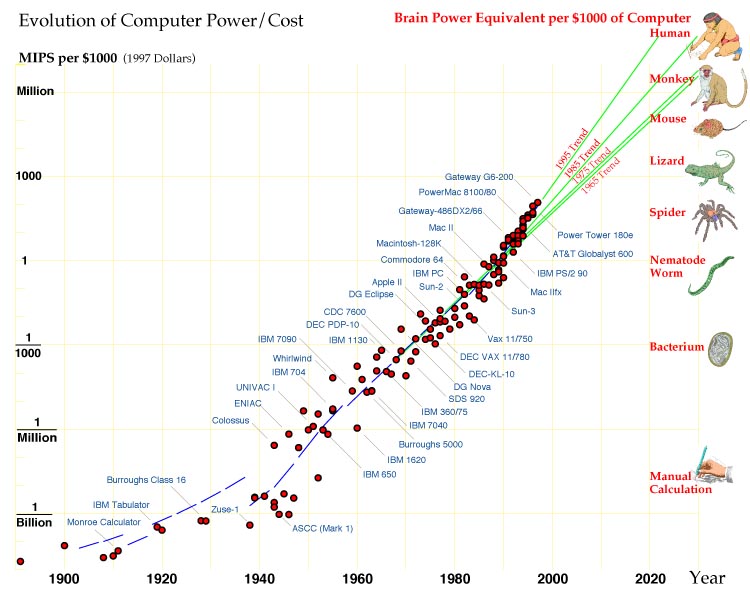
At the present rate, computers suitable for humanlike robots will appear in the 2020s. Can the pace be sustained for another three decades? The graph shows no sign of abatement. If anything, it hints that further contractions in time scale are in store. But, one often encounters thoughtful articles by knowledgeable people in the semiconductor industry giving detailed reasons why the decades of phenomenal growth must soon come to an end.
I don't know where to look to confirm that can current computers do 1 billion MIPS (Million Instructions per Second?) as predicted by this article?
The promise of Instruction per Second scaling forever did stop being super-exponential. Instead of CPU based Instructions per Second we have continued scaling compute with GPU based Floating-point Operations Per Second which don't exactly have a 1:1 equivalence with instructions but are close enough. Nvidia released the "first" GPU in 1999 so it's not too surprising that this guy wasn't thinking in those terms in 1998. That's why Kurzweil and Bostrom used FLOPS in their extrapolations. They also end up in the neighborhood of 2020s/2030s in their later predictions in the 2000s.
With that in mind we are currently at 1 billion GigaFLOPS for the largest super computer in 2023. And the trendline since the 90's has kept up with the prediction made in the post. Although we can't exactly say 1 GigaFLOPS = 1000 MIPS.
When the article was written, almost nobody cared about GPUs or similar architectures being really good at parallel computation.
So while he wrote about MIPS, and those have indeed basically stopped significantly improving, FLOPS have continued to improve. And for AI in particular, for inference at least, we can get away with 8 bit floats, which is why my phone does 1.58e13/second, only a factor of x60 from a million-billion.
Today we'd include the GPU. If we include supercomputers, we really have to compare total global capacity, which is on the order of 1 million times that of 1997 [0]. That basically fits his trend line.
> I don't know where to look to confirm that can current computers do 1 billion MIPS (Million Instructions per Second?) as predicted by this article?
An RTX 4090 has AI compute of up to 661 teraflops in FP16[1]. FLOPS and IPS are not interchangeable, but just for fun, that's 6.6 * 10^14 FLOPS, which is just short of 1 billion million (10^15).
I'm not sure he predicts a billion mips. The graph tops out at a million mips per $1000. He figues brain equivalence is 100 million mips. If you assume mips are equivalent to flops then that's 100 teraflops. That would seem roughly to match:
What I find incredible about the progress of computing power is that there isn't anything that actually makes Moore's law a given. Engineers keep discovering advances in materials science and manufacturing that enable advancements on such a consistent pace. Is this a fluke? Luck? What enables this?
Tens of billions of dollars of investment specifically to keep up with Moore's Law.
It's basically akin to something like the Manhattan Project or the Apollo Program, just something initiated by private corporations rather than a government-directed investment program.
The market does. New stuff needs to be sold every year, and needs to be some amount faster to find a buyer. The cost of development is minimized while still reaching that goal, limiting the gain to no more than necessary.
Except for the scale on the right. Which suggests that the nematode worm could be simulated reliably in 1998, but here we are in 2024 and still can't do it...
Moravac (in the linked paper): "In both cases, the evidence for an intelligent mind lies in the machine's performance, not its makeup."
Do you agree?
I'm much less keen to ascribe "intelligence" to large, pretrained language
models given that I know how primitive their training regime is compared to
a scenario where I might have been "blended" by their ability to "chat" (double
quote here since I know ChatGPT and the likes do not have a memory, so all
prior interactions have to be re-submitted with each turn of a conversation).
Intuitively, I'd be more prone to ascribe intelligence based on convincing
ways of construction that go along with intellignece-like performance, especially if the model also makes human-like errors.
I agree with Moravec. As he points out a bit later on:
> Only on the outside, where they can be appreciated as a whole, will the impression of intelligence emerge. A human brain, too, does not exhibit the intelligence under a neurobiologist's microscope that it does participating in a lively conversation.
We only have fuzzy definitions of "intelligence", not any essential, unambiguous things we can point to at a minute level, like a specific arrangement of certain atoms.
Put another way, we've used the term "intelligent" to refer to people (or not) because we found it useful to describe a complex bundle of traits in a simple way. But now that we're training LLMs to do things that used to be assumed to be exclusively the capacity of humans, the term is getting stretched and twisted and losing some of its usefulness.
Maybe it would be more useful to subdivide the term a bit by referring to "human intelligence" versus "LLM intelligence". And when some new developments in AI seem like they're different from "LLM intelligence", we can call them by whatever distinguishes them, like "Q* intelligence", for example.
Agreed, kind of similar to the trope of 'virtual intelligences' vs 'artificial intelligences' in sci-fi, where VIs are a lot more similar to LLM intelligence (imitative, often unable to learn, able to make simple inferences and hold basic conversation but lacking that instantly recognizable 'spark' of an intelligent being that we can see in humans - especially kids - and some other animals) rather than AIs, which are 'true' intelligences comparing to or exceeding humans in every way.
> The intelligence of a system is a measure of its skill-acquisition efficiency over a scope of tasks, concerning priors, experience, and generalization difficulty.
Priors here means how targeted is the model design to the task. Experience means how large is the necessary training set. Generalization difficulty is how hard is the task.
So intelligence is defined as ability to learn a large number of tasks with as little experience and model selection as possible. If it's a skill only possible because your model already follows the structure of the problem, then it won't generalize. If it requires too much training data, it's not very intelligent. If it's just a set number of skills and can't learn new ones quickly, it's not intelligent.
Your final paragraph is a poor definition of human level intelligence.
Yes, learning is an important aspect of human cognition. However, the key factor that humans possess that LLMs will never possess, is the ability to reason logically. That facility is necessary in order to make new discoveries based on prior logical frameworks like math, physics, and computer science.
I believe LLMs are more akin to our subconscious processes like image recognition, or forming a sentence. What’s missing is an executive layer that has one or more streams of consciousness, and which can reason logically with full access to its corpus of knowledge. That would also add the ability for the AI to explain how it reached a particular conclusion.
There are likely other nuances required (motivation etc.) for (super) human AI, but some form of conscious executive is a hard requirement.
From that article: "actual contents of minds are tremendously, irredeemably complex".
But they're not. The "bitter lesson" of machine learning is that the primitive operations are really simple. You just need a lot of them, and as you add more, it gets better.
Now we have a better idea of how evolution did it.
Take a look at Turing words in his formulation of the Turing machine and I think it becomes quite clearly the man spent time thinking about what he is doing when he is doing computations.
The tape is a piece of paper, the head is the human, who is capable of reading data from the tape and writing to it. The symbols are discernible things on the paper, like numbers. The movement of the tape ("scanning") is the eyes going back and forth. At each symbol, the machine decides which rule to apply.
Its an inescapable fact that we are trying to get computers to 1. operate as close to how we think (as we are the ones who operate it) and 2. to produce results which resemble how we think.
Abstractions, inheritence, objects, etc are no doubt all heavily influenced by thinking about how we think. If we still programmed using 1s and 0s, we wouldnt be where we are.
It seems incredibly short sighted to me to believe that because a few decades of research hasnt panned out, that we should all together forget about it.
Turing's original paper [1] seems to have no such anthropocentric bias. His description is completely mechanical. Out of curiosity, rather than disputativeness, do you remember where you saw that sort of description? Turing's Computing Machinery and Intelligence paper seems to meticulously exclude that sort of language as well.
You have read me backwards. I am firmly of the opinion that the last few decades of research has entirely and completely panned out. The topic is clearly in the mind of theorists in 1950. But I'm pretty sure early computer architects were more interested in creating better calculators than in creating machines that think.
There is a ton. What I said isn't much of my own interpretation, its Turing own description of the machine.
The first section of the paper literally says "We may compare a man in the process of computing a real number to
machine which is only capable of a finite number of conditions", gives a human analogue for every step/component of the process, continuously refers to the machine as a "he/him", and continuously gives justifications from human experience.
"We have said that the computable numbers are those whose decimals
are calculable by finite means. This requires rather more explicit
definition. No real attempt will be made to justify the definitions given
until we reach § 9. For the present I shall only say that the justification
lies in the fact that the human memory is necessarily limited.
We may compare a man in the process of computing a real number to
machine which is only capable of a finite number of conditions q1: q2. .... qI;
which will be called " m-configurations ". The machine is supplied with a
"tape " (the analogue of paper) running through it, and divided into
sections (called "squares") each capable of bearing a "symbol". At
any moment there is just one square, say the r-th, bearing the symbol <2>(r)
which is "in the machine". We may call this square the "scanned
square ". The symbol on the scanned square may be called the " scanned
symbol". The "scanned symbol" is the only one of which the machine
is, so to speak, "directly aware". However, by altering its m-configuration the machine can effectively remember some of the symbols which
it has "seen" (scanned) previously."
"Computing is normally done by writing certain symbols on paper. "We
may suppose this paper is divided into squares like a child's arithmetic book.
In elementary arithmetic the two-dimensional character of the paper is
sometimes used. But such a use is always avoidable, and I think that it
will be agreed that the two-dimensional character of paper is no essential
of computation. I assume then that the computation is carried out on
one-dimensional paper, i.e. on a tape divided into squares"
"The behaviour of the computer at any moment is determined by the
symbols which he is observing, and his " state of mind " at that moment.
We may suppose that there is a bound B to the number of symbols or
squares which the computer can observe at one moment. If he wishes to
observe more, he must use successive observations. We will also suppose
that the number of states of mind which need be taken into account is finite.
The reasons for this are of the same character as those which restrict the
number of symbols. If we admitted an infinity of states of mind, some of
them will be '' arbitrarily close " and will be confused."
"We suppose, as in I, that the computation is carried out on a tape; but we
avoid introducing the "state of mind" by considering a more physical
and definite counterpart of it. It is always possible for the computer to
break off from his work, to go away and forget all about it, and later to come
back and go on with it. If he does this he must leave a note of instructions
(written in some standard form) explaining how the work is to be continued. This note is the counterpart of the "state of mind". We will
suppose that the computer works in such a desultory manner that he never
does more than one step at a sitting. The note of instructions must enable
him to carry out one step and write the next note."
"The
differences from our point of view between the single and compound symbols
is that the compound symbols, if they are too lengthy, cannot be observed
at one glance. This is in accordance with experience. We cannot tell at
a glance whether 9999999999999999 and 999999999999999 are the same"
Taken all this together, I don't think its far fetched to think Turing was very much thinking about the individual steps he was taking when doing calculations manually on a piece of graph paper, while trying to figure out how to formalize it.
Perhaps you disagree, but saying its "completely mechanical" is surely false, no?
Can't we consider the context window to be memory?
And eventually wont we have larger and larger context windows, and perhaps even individual training where part of the context window 'conversation' is also fed back into the training data?
Reducing the capability of the human brain to performance alone is too simplistic, especially when looking at LLM's. Even if we would assign some
intelligence to LLM's, they need a 400w GPU at inference time, and several orders of magnitude more of those at training time. The human brain runs constanly at ~20w.
I highly doubt you'd be able to get even close to that kind of performance with current manufacturing processes. We'd need something entirely different from laser lithography for that to happen.
The problem isn't the manufacturing process, but rather the architecture.
At a low level: We take an analog component, then drive it in a way that lets us treat it as digital, then combine loads of them together so we can synthesise a low-resolution approximation of an analog process.
At a higher level: We don't really understand how our brains are architected yet, just that it can make better guesses from fewer examples than our AI.
Also, 400 W of electricity is generally cheaper than 20 W of calories (let alone the 38-100 W rest of body needed to keep the brain alive depending on how much of a couch potato the human is).
> Also, 400 W of electricity is generally cheaper than 20 W of calories
Are you serious? I don't think you have to be an expert to see that the average human can perform more work per energy intake than the average GPU.
> The problem isn't the manufacturing process, but rather the architecture.
It's very much a problem, good luck trying to even emulate the 3D neural structure of the brain with lithography. And there are few other processes that can create structures at the required scale, with the required precision.
> Are you serious? I don't think you have to be an expert to see that the average human can perform more work per energy intake than the average GPU.
You're objecting to something I didn't say, which is extra weird because I'm just running with the same 400 W/20 W you yourself gave. All I'm doing here is pointing out that 400 W of electricity is cheaper than 20 W of calories especially as 20 W is a misleading number until we get brains in jars.
To put numbers to the point, at $0.10/kWh * 400 W * 24h = $0.96, while the UN definition for abject poverty is $2.57 in 2023 dollars.
As for my opinion on which can perform more work per unit of energy, that idea is simply too imprecise to answer without more detail — depending on what exactly you mean by "work", a first generation Pi Zero can beat all humans combined while the world's largest supercomputer can't keep up with one human.
> It's very much a problem, good luck trying to even emulate the 3D neural structure of the brain with lithography.
IIRC by volume a human brain mostly communication between neurones; the ridges are because most of your complexity is a thin layer on the surface, and ridges get you more surface.
But that doesn't even matter, because it's a question of the connection graph, and each cell has about 10,000 synapses, and that connectivity be instantiated in many different ways even on a 2D chip.
We don't have a complete example connectivity graph for a human brain. Got it for a rat, I think, but not a human, which is why I previously noted that we don't really understand how our brains are architected.
> And there are few other processes that can create structures at the required scale, with the required precision.
Litho vastly exceeds the required precision. Chemical synapses are 20-30 nm from one cell to the next, and even the more compact electrical synapses are 3.5 nm.
Most likely because any brains that required more energy died off at evolutionary time scales. And while there are some problems with burning massive amounts of energy to achieve a task (see: global warming) this is not likely a significant short falling that large scale AI models have to worry about. Seemingly there are plenty of humans willing to hook them up to power sources at this time.
Also you might want to consider the 0-16 year training stages for human which have become more like 0-21 year training stages with at minimum 8 hours of downtime per day. This does adjust the power dynamics pretty considerably in that the time actually thinking daily drops to around 1/3rd the day boosting effective power use to 60w (as in you've wasted 2/3s the power eating, sleeping, and pooping). In addition that model you've spend a lot of power training is able to be duplicated across thousands/millions of instances in short order, where as you're praying that human you've trained doesn't step out in front of a bus.
So yes, reducing the capability of a human brain/body to performance alone is far too simplistic.
Given their performance, I think it is important to pay attention to their weirdnesses — I can call them "intelligent" or "dumb" without contradiction depending on which specific point is under consideration.
Transistors outpace biological synapses by the same degree to which a marathon runner outpaces continental drift. This speed difference is what allows computers to read the entire text content of the internet on a regular basis, whereas a human can't read all of just the current version of the English language Wikipedia once in their lifetime.
But current AI is very sample-inefficient: if a human were to read as much as an LLM, they would be world experts at everything, not varying between "secondary school" and "fresh graduate" depending on the subject… but even that description is misleading, because humans have the System 1/System 2[0] distinction and limited attention[1], whereas LLMs pay attention to approximately everything in the context window and (seem to) be at a standard between our System 1 and System 2.
If you're asking about an LLM's intelligence because you want to replace an intern, then the AI are intelligent; but if you're asking because you want to know how many examples they need in order to decode North Sentinelese or Linear A, then (from what I understand) these AI are extremely stupid.
It doesn't matter if a submarine swims[2], it still isn't going to fit into a flooded cave.
I used to think this too, but now I'm not so sure.
There's an influential school of thought arguing that one of the primary tasks of the brain is to predict sensory input, e.g. to take sequences of input and predict the next observation. This perspective explains many phenomena in perception, motor control, and more. In an abstract sense, it's not that different from what LLMs do -- take a sequence and predict the next item in a sequence.
The System 1 snd System 2 framework is appealing and quite helpful, but let's unpack it a little. A mode of response is said to be "System 1" if it's habitual, fast, and implemented as a stimulus-response mapping. Similar to LLMs, System 1 is a "lookup table" of actions.
System 2 is said to be slow, simulation-based, etc. But tasks performed via System 2 can transition to System 1 through practice ('automaticity' is the keyword here). Moreover, pre-automatic slow System 2 actions are compositions are simpler sets of actions. You deliberate about how to compose a photograph, or choose a school for your children, but many of the component actions (changing a camera setting, typing in a web URL) are habitual. It seems to me that what people call System 2 actions are often "stitched-together" System 1 behaviors. Solving calculus problem may be System 2, but adding 2+3 or writing the derivative of x^2 is System 1. I'm not sure the distinction between Systems 1 and 2 is as clear as people make it out to be -- and the effects of practice make the distinction even fuzzier.
What does System 2 have that LLMs lack? I'd argue: a working memory buffer. If you have working memory, you can then compose System 1 actions. In a way, a Turing machine is System 1 rule manipulation + working memory. Chain-of-thought is a hacky working memory buffer, and it improves results markedly. But I think we could do better with more intentional design.
> if a human were to read as much as an LLM, they would be world experts at everything
It would take a human more than one lifetime to read everything most LLMs have read. I often have trouble remembering specifics of something I read an hour ago, never mind a decade ago. I can't imagine a human being an expert in something they read 300 years ago.
For reference, I believe relatively rudimentary chatbots have been able to pass forms of the Turing Test for a while, while also being unable to do almost all the things humans can do. It turns out you can make a chatbot quite convincing for a very short conversation with someone you've never met over the internet[1]. I think there's a trend that fooling perception is significantly easier than having the right capabilities. Maybe with sufficiently advanced testing you can judge, but I don't think this is the case in general: in general, our thoughts may be significantly different than we can converse. One obvious example is simply people with disabilities (say a paraplegic) who can't talk at all (while having thoughts of their own): output capability need not necessarily reflect internal capability.
Also, take this more advanced example: if you built a sufficiently large lookup table (of course, you need (possibly human) intelligence to build it, and it would be of impractical size), you can build a chatbot completely indistinguishable from a human that nonetheless doesn't seem like it really is intelligent (or conscious for that matter). The only operations it would perform would be some sort of decoding of the input into an astronomically large number to retrieve from the lookup table, and then using some (possibly rudimentary) seeking apparatus to retrieve the content that corresponds to the input. Your input size can be arbitrarily large enabling arbitrarily long conversations. It seems that to judge intelligence we really need to examine the internals and look at their structure.
I have a hunch that our particular 'feeling of consciousness' stems from the massive interconnectivity of the brain. All sorts of neurons from around the brain have some activity all the time (I believe the brain's energy consumption doesn't vary greatly with activity, so we use it), and whatever we perceive goes through an enormous number of interconnected neurons (representing concepts, impressions, ideas, etc.); unlike typical CPU-based algorithms that process a somewhat large number (potentially 100s of millions) of steps sequentially. My intuition does seem to pair with modern neural architectures (i.e. they could have some consciousness?), but I really don't know how we could do this sort of judgement before understanding better the details of the brain and other properties of cognition. I think this is a very important research area, and I'm not sure we have enough people working on it or using the correct tools (it relies heavily on logic, philosophy and metaphysical arguments; as well as require personal insight from being conscious :) ).
Moravec also wrote a book much along these lines in the late 80's (Mind Children).
If I recall correctly, a good part of it was also about the idea of "transferring" human consciousness into a machine "host". The idea being that a sufficiently advanced computer would be able to somehow make sense of a human's neuron mappings and then "continue running" as that individual.
It was provocative back then, and still is!
The idea of having my consciousness continue its existence indefinitely in somebody's kubernetes cluster, however, seems like a very special vision of hell.
It's a tough question since we still don't understand the brain well enough to know what degree of fidelity of copying it is necessary to achieve the same/similar functionality.
What is the computational equivalent of a biological neuron? How much of the detailed chemistry is really relevant to it's operation (doing useful computation), or can we just use the ANN model of synapses as weights, and the neuron itself as a summation device plus a non-linearity?
Maybe we can functionally model the human brain at a much coarser, more efficient, level than individual neurons - at cortical mini/macro column level perhaps, or as an abstract architecture not directly related to nature's messy implementation?
At my workplace, we are now completing the multiscale simulation of a full mouse brain (neuron/synaptic activity, cellular metabolism, etc). It fits into our small supercomputer first deployed in 2019, and there's a large potential for simplification not yet realized.
I believe that a supercomputer from the top 5 can already simulate a human brain. But we don't have the data and the theory yet. We are developing it, though.
Are you talking about real time or faster simulation of complete cellular metabolism incl. neural activity across an entire mouse brain? If not, then I'd say I can run a simulation like this on my home computer. It will just take forever to compute something meaningful. But if yes, that is insanely impressive, even though this won't scale to the human brain any time soon since it has 1000x more neurons and exponentially more synapses.
Hmm, this reasoning is making a lot of really questionable assumptions:
> We’ll use the estimates of 100 billion neurons and 100 trillion synapses for this post. That’s 100 teraweights.
... or maybe actual synapses cannot be described with a single weight.
> The max firing rate seems to be 200hz [4]. I really want an estimate of “neuron lag” here, but let’s upper bound it at 5ms.
... but ANNs output float activations per pass. Biological neurons encode values with sequences of spikes which vary in timing, so the firing rate doesn't on its own tell you the rate at which neurons can communicate new values.
> Remember also, that the brain is always learning, so it needs to be doing forward and backward passes. I’m not exactly sure why they are different, but [6] and [7] point to the backward pass taking 2x more compute than the forward pass.
... but the brain probably isn't doing backprop, in part because it doesn't get to observe the 'correct' output, compute a loss, etc, and because the brain isn't a DAG.
{kind=link}
{kind=link}
* 86 billion neurons in a brain [1]
* 400 transistors to simulate a synapse [2]
That's 34 trillion, 400 billion transistors to simulate a human brain.
As of 2024, the GB200 Grace Blackwell GPU has 208 billion MOSFETs[3]. In 2023, AMD's MI300A CPU had 146 billion transistors[3]. In 2021, the Versal VP1802 FPGA had 92 billion transistors[3]. Intel projects 1 trillion by 2030; TSMC suggests 200 billion by 2030.
We'll likely have real-time brain analogs by 2064.
(Aside, these are the dates I've used in my hard sci-fi novel. See my profile for details.)
[1]: https://pubmed.ncbi.nlm.nih.gov/19226510/
[2]: https://historyofinformation.com/detail.php?id=3901
[3]: https://en.wikipedia.org/wiki/Transistor_count
reply